
Notice
Recent Posts
Recent Comments
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 머신러닝
- WTI
- 스크리닝
- 주가분석
- 제다큐어
- 반려견치매
- 경제위기
- 퀀트
- 국제유가
- Python
- 금리인상
- 넬로넴다즈
- 중국경제
- 코로나19
- 유상증자
- prometheus
- 미국금리
- FOMC
- 마법공식
- 엘론 머스크
- 중국증시
- 뇌졸중
- WTI유
- 지엔티파마
- 뉴지스탁
- 아모레퍼시픽
- DSP
- 기업분석
- 테슬라
- 주식투자
Archives
- Today
- Total
Data Analysis for Investment & Control
BeautifulSoup4를 이용한 크롤링 준비하기 본문
반응형
이 포스트는 개인적으로 Python을 공부하는 과정에서 추후 리마인드를 위해 작성합니다.
이번 글에서는 평소부터 관심 있었던 웹 크롤링Web Crawling이라는 주제를 가지고 Python을 이용하여 구현해 보는 것을 다루어 보는데, 그 과정에서 필요한 몇 가지 라이브러리를 소개하고자 한다.
구글링을 통해 Python 웹 크롤링이라는 것을 검색해 보면 나오는 라이브러리가 BeautifulSoup과 Scrapy라는 것이 있다. Scrapy에 대해서는 나중에 기회가 되면 따로 다루기로 하고, BeautifulSoup이라는 것은 웹 페이지의 Html 포맷 문서를 처리하기 쉽게 전처리 해주는 라이브러리라고 알려져 있는데 이를 이용해 특정 웹 사이트의 웹 문서를 얻어오는 것을 다루어 보고자 한다.
우선 PIP를 이용해 BeautifulSoup4를 설치하도록 하자. 커맨드 창을 열어 다음과 같이 타이핑 한다.
C:\Python27\Script>pip install beautifulsoup4
※ pip.exe가 C:\Python27\Script 경로에 있으므로 해당 위치에서 위의 명령을 수행하도록 하자.

이미 설치가 되어 있기 때문에 설치 프로세스가 진행되지 않는다.
이런식으로 라이브러리를 설치하게 되면 C:\Python27\Lib\site-packages 폴더에 위치하게 된다. 모듈에 따라서 사용자가 직접 파일을 다운 받아 설치할 수도 있는데, 해당 경로에 압축을 풀어 설치하면 된다.
설치가 되면 PyCharm 같은 경우는 왼쪽 설치된 라이브러리 목록에 나타나게 된다. 모듈을 사용하기 위해서는 아래와 같이 코드 상에서 import를 시켜주도록 하자.
from bs4 import BeautifulSoup
BeautifulSoup의 사용법은 구글링을 해보면 많은 예제를 찾을 수가 있다. 여기서는 간단히 타겟 웹사이트의 HTML 문서 정보를 추출하고자 한다.
import urllib2
from bs4 import BeautifulSoup
targetUrl = "http://www.hankyung.com/"
maxBuf = 10685760
doc = urllib2.urlopen(targetUrl)
soup = BeautifulSoup(doc.read(maxBuf), 'lxml')
print soup
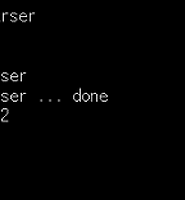
위 테스트 코드에서 urllib2는 Python에 내장된 기본 라이브러리임을 참조하자. 테스트는 한국경제 웹사이트로 하고 url을 열어 BeautifulSoup 함수를 사용하여 웹 문서를 텍스트로 출력한다.

프로그램을 실행하면 출력 창에 Html 문서 구조를 확인할 수 있다.
이번 글에서는 웹 크롤링 시에 기본이되는 타겟 URL에서의 문서 정보를 얻어오는 것을 간단하게 알아보았다. 이는 웹 크롤링 기능에서 기본이 되는 것으로 추출된 문서에서 내가 원하는 정보를 추출하고 어떤 의미인지 파악하는 기능, 이 웹 문서와 연결된 링크를 통해 다른 웹 문서의 정보 추출로 이어지는 기능, 일련의 작업들을 지정된 시간에 정기적으로 수행하도록 하는 기능, 모아진 유료 정보를 정리해서 DB에 모아주는 기능 등의 구현으로 이어진다.
다음에는 얻어진 웹 문서로부터 다른 웹 문서로 이동하기 위한 링크 추출 작업과 이에 필요한 HTMLParser라는 모듈에 대해 알아보도록 하겠다.
(내용이 마음에 드셨다면 아래의 '공감' 버튼을 눌러주세요^^)
반응형
'Code > Python' 카테고리의 다른 글
| Python 기반 MySQL 연동하기 (1) | 2016.06.23 |
|---|---|
| Python 클래스로 프로그래밍 하기 (0) | 2016.06.23 |
| Python을 이용한 웹 크롤링 - HTMLParser를 이용한 링크 추출 (0) | 2016.06.21 |
| Python 에디터 PyCharm 설치 (0) | 2016.06.19 |
| Python 개발환경 설정 (2) | 2016.06.19 |
'Code/Python' Related Articles
more

Comments